2020-06-02 09:50:04 0
AI视觉检测机器系统
使用深度学习进行缺陷检测
视觉检查系统中检测均匀背景对象(细线,缎纹等)中各种缺陷的技术。在制造业领域中,最近出现了“人力资源短缺”和“消费者需求多样化”的趋势,并且对自动视觉检查系统的需求也在增加。然而,现有的检查系统不能适应多种物体/缺陷类型。我们构建了深度学习模型,可以预先学习各种缺陷类型,从而构建了一个缺陷检测系统,该系统使任何人都可以像人眼一样自动执行检查,而无需进行任何复杂的设置。
简介
1.1背景
在制造领域,人力资源短缺和客户需求的多样化已经变得更加多样化,并且对视觉检查系统的自动化的需求也在增加。然而,现有的图像传感器仅使检查过程自动化的一部分可行。原因如下:由于要制造的物体种类繁多,这种传感器不能适应要检查的物体的各种材料和形状;除非具备丰富的专业知识,否则无法进行调整。为此,我们的目标是实现一种自动化的外观检查技术,该技术可以满足适用于多种对象和缺陷类型的要求,并且任何人都可以轻松设置以实现检查过程的自动化。
为了处理各种对象和缺陷类型,检测缺陷的算法,突出显示缺陷的输入(照明/成像)技术以及适应对象轮廓的驱动技术都是必需的。在本文中,我们提出了一种用于检测各种缺陷的缺陷检测算法。
1.2使用深度学习进行预训练类型缺陷检测的建议
在深度学习方法带来各种图像分析结果的情况下,瓶颈在于图像的收集。为了实际实现用于视觉检查的深度学习,用于学习的图像的收集将对现场工作人员构成巨大的负担,从而使得在启动产品线时难以确保足够数量的学习图像。在本文中,为解决该问题,我们提出了视觉检查的自动化方法,其中应用了不需要为每个产品系列准备学习图像的预训练类型算法。
在目视检查中,仅需检测各种物体表面和缺陷类型中细微或细微差异的缺陷。如表1所示,可以对进行目视检查的对象和缺陷类型进行分类。在分类检查中,已经与现有图像传感器一起实际使用的检查仅限于在统一背景下进行的显着缺陷检查。另一方面,本文提出的算法可以应用于均匀物体中的小缺陷或弱缺陷。因为一个统一的对象甚至在不同的产品系列中都显示相似的特征,所以预训练类型算法可以很好地工作。

2.系统概述
图1是检测处理的图示。特征图通过使用卷积神经网络(CNN)的预训练类型处理输入图像来表达可能的缺陷级别。此后,如此获得的特征图被二值化并提取为缺陷区域。
图1检验系统概要
用于执行此类任务的深度学习研究案例通常基于包括对象检测和语义分割的算法,以输出处理结果1)。另一方面,本文提出的算法将特征图设置为最终输出。这是因为,对于实际的生产现场,对于每个产品线,关于产品缺陷是被归类为缺陷产品还是被认为是合格产品的判断是不同的,因此需要留出空间来设置阈值对于各行。实际的操作模型假设在生成特征图(其中仅缺陷部分由所提出的算法突出显示)并在图像传感器上进行简单图像处理的二值化或标记后,将该算法用作一系列检查流程的一部分被申请;被应用; 因此,通过使用任何缺陷的位置和大小来执行验收判断。
3.生成缺陷检测图像的算法
在制造现场进行的缺陷检查中,假设可能会在图像中投影除缺陷以外的对象,并且在后处理阶段可能需要对缺陷和其他对象进行分类。因此,应该安排成可以通过特征图来标识位置和尺寸,在特征图中可以对缺陷的可能程度成像。这种特征图的准备包括以下两个步骤(图2)。
(1)假设检查图像中存在缺陷的可能性
(2)缺陷的估计位置的识别和成像
首先,对于步骤(1),将检查图像输入到CNN中,并输出图像中可能存在缺陷的可能性,可能性为0到1。CNN的排列方式是,当图案更接近缺陷时会输出较高的值通过允许从许多缺陷图像中预先学习,可以将这些元素包含在检查图像中。
接下来,对于步骤(2),确定从检查图像内的哪个位置导出在(1)中估计出的缺陷的概率。使用CNN,表示缺陷位置的信息包含在各个中间层的计算结果中2)并且,通过使用该信息,可以以检查图像像素为单位计算出对缺陷概率的贡献度。最后,将每个像素的贡献度乘以适当的放大倍率,从而创建特征图。
图3是特征图的示例。在该图中,随着对缺陷概率的贡献程度变高,颜色从蓝色变为红色。在检查图像中已知存在缺陷的部分显示出较高的值。
4.学习图像数据库
为了使预学习型算法发挥全部性能,在开发时有必要构建一个大型的学习图像数据库(DB),该数据库涵盖制造现场生产的各种对象。但是,由于并不总是保存实际的产品线数据,并且这些数据通常可能是机密的,因此出于开发用途的目的收集数据并不容易。特别地,对于包含缺陷的图像数据,还存在绝对数较小且优质产品的数据量不平衡的问题。
作为在可获得可学习图像的条件下构建数据库的方法,将由计算机图形学(CG)或生成对抗网络(GAN)生成的伪图像的方法用作学习图像3),4),但很少在实际环境中显示出有效性的情况。
因此,参照本文提出的算法的发展,实际创建并成像了包含缺陷类型,位置,大小,颜色,背景材料和光源设置的组合的对象的模式,从而构建了数据库。图4显示了实际创建的组合模式的示例。

为了进行学习处理,在将图像数量增加到800万之后,使用了通过添加包括裁剪和添加噪声的数据增强而获得的图像。DB的使用允许本文中提出的算法在制造现场处理各种对象和缺陷类型。
5.关于更高速度的考虑
通常,来自GPU的大量计算资源可用于实施深度学习。然而,对于在制造现场使用的图像传感器,由于诸如成本的问题,难以使用这种资源。因此,为了通过使用CPU的处理来提高高速性能,应将注意力集中在占用CNN处理时间的调用层上,从而针对图像传感器的硬件配置优化网络结构和线缆安装类型。根据输入图像的分辨率,这种布置实现了100 ms至600 ms的处理时间。
5.1优化网络结构
尽管已经提出了几种精密深度学习网络,但是许多网络都假定使用GPU,并且在大多数情况下,CPU中图像传感器的处理时间超过1000毫秒。本文提出的算法所采用的网络是基于ResNet的5) 或开始6),这是用于一般对象识别任务的高精度和高速网络的典型代表。此外,考虑到网络的每一层都可以结合多种缺陷和背景图案进行处理,因此结构上要优先考虑有效接收场的多功能性7),8)以及多样化的高速结构 9) 具有特色,从而同时确保速度和精度。
5.2核近似
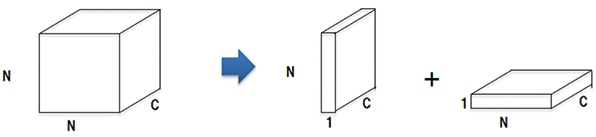
对于卷积运算,计算量与内核大小成比例地增加,因此,随着内核大小变小,可以获得更高的速度。另一方面,对于CNN,可以通过使用多个较小尺寸的卷积层来获得等效于较大尺寸内核的卷积层的效果。10)。因此,我们将内核大小为NxNxC的卷积层划分为包括1xNxC和Nx1xC两个阶段的两个阶段,从而缩短了总体计算时间。(图5)
5.3并行操作指令的定点表示与利用
卷积是浮点数据行的乘积和运算。另一方面,对于图像传感器采用的CPU,可以使用并行执行多个数据的积和运算的单指令多数据(SIMD)。此外,SIMD还可以执行更多并行操作,作为表示数据的位数。参考卷积计算,通过实现输入和输出的8位定点表示,我们最多可以执行32个并行操作。
6.绩效评估
我们将本文提出的算法应用于466个检查图像(对于优质产品为62个图像;对于次品为404个图像)以评估性能。用于比较的传统方法的精度是通过针对每个对象优化流行的滤镜(包括对比度增强和合并到图像传感器中的边缘检测)来优化的,从而提取缺陷区域。但是请注意,用于评估的图像是成像环境和成像对象与本文采用的学习图像不同的图像。
表2显示了性能评估的结果。类别“假阳性”表示从良好的产品图像中检测到错误,而“假阴性”表示未检测到有缺陷的产品图像。
表2绩效评价结果
假阴性 假阳性
常规方法 3.2% 6.7%
拟议方法 0.9% 3.4% 该方法的假阳性和假阴性结果均显示出较高的精度。另外,虽然常规方法需要选择多个滤波器并针对每个对象调整几个参数,但是使用所提出的方法需要调整的参数仅是特征图的阈值,并且减少了调整的时间和精力。可以在生产现场进行工作。
该方法的假阳性和假阴性结果均显示出较高的精度。另外,虽然常规方法需要选择多个滤波器并针对每个对象调整几个参数,但是使用所提出的方法需要调整的参数仅是特征图的阈值,并且减少了调整的时间和精力。可以在生产现场进行工作。
图6和7显示了使用提出的算法提取缺陷区域的结果。图的第一行示出了输入图像,第二行示出了使用结合在图像传感器中用于比较的常规方法从输入图像中提取缺陷区域的结果。最后的第三行显示了使用提出的算法提取缺陷区域的结果。图6示出了图像包含与学习图像相似的图案的情况的结果,图6(a)示出了缎面抛光的铝被划伤的物体。划痕的宽度约为 4像素的分辨率足以满足约4像素的要求。对比度低的输入图像的2000×2000,并且用常规方法进行的加工根本无法提取划痕。另一方面,所提出算法的处理结果能够提取划痕区域,这是常规方法无法实现的,并且它忽略了在与划痕相邻的图像区域上显示出显着显着对比度的照明阴影。地区。图6(b)示出了在其上具有污渍的塑料膜。该膜具有细的发际线,并且当用常规方法处理图像时,源自发际线的噪声在工作中很普遍。相反,所提算法的处理结果表明,缺陷区域可以更清晰地提取而不受细线的影响。所提算法的处理结果能够提取出常规方法无法实现的划痕区域,并且忽略了在与划痕区域相邻的图像区域上显示出更高显着对比度的照明阴影。图6(b)示出了在其上具有污渍的塑料膜。该膜具有细的发际线,并且当用常规方法处理图像时,源自发际线的噪声在工作中很普遍。相反,所提算法的处理结果表明,缺陷区域可以更清晰地提取而不受细线的影响。所提算法的处理结果能够提取出常规方法无法实现的划痕区域,并且忽略了在与划痕区域相邻的图像区域上显示出更高显着对比度的照明阴影。图6(b)示出了在其上具有污渍的塑料膜。该膜具有细的发际线,并且当用常规方法处理图像时,源自发际线的噪声在工作中很普遍。相反,所提算法的处理结果表明,缺陷区域可以更清晰地提取而不受细线的影响。它忽略了在与划痕区域相邻的图像区域上显示更高对比度的照明阴影。图6(b)示出了在其上具有污渍的塑料膜。该膜具有细的发际线,并且当用常规方法处理图像时,源自发际线的噪声在工作中很普遍。相反,所提算法的处理结果表明,缺陷区域可以更清晰地提取而不受细线的影响。它忽略了在与划痕区域相邻的图像区域上显示更高对比度的照明阴影。图6(b)示出了在其上具有污渍的塑料膜。该膜具有细的发际线,并且当用常规方法处理图像时,源自发际线的噪声在工作中很普遍。相反,所提算法的处理结果表明,缺陷区域可以更清晰地提取而不受细线的影响。
图7显示了与学习图像有很多差异并且背景区域有信息时对象的输出结果。图7(a)示出了在铁氧体芯上产生裂纹的图像,并且在学习图像中不存在包含该类型的信息的图像。当用常规方法对该图像进行处理时,尽管可以提取裂纹区域,但也可以提取铁氧体磁心的形状和源自表面粗糙度的边缘。另一方面,该算法的处理结果表明,只有裂纹区域作为缺陷区域输出。图7(b)示出了图像,其中木制智能手机盖上存在灰尘。学习图像不包括木制物体的图像,并且不存在其中包括灰尘作为缺陷的图案,因为这种图案不是当前开发中的目标。当用常规方法加工该物体时,不仅灰尘,而且木纹部分也以相似的强度被提取。另一方面,使用提出的算法进行处理后发现,尽管没有学习木材图案和灰尘,但灰尘可能会作为缺陷而输出,而忽略了木材图案。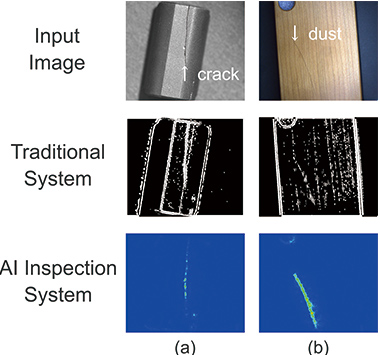
结果表明,尽管本文提出的算法属于预学习类型,但它具有响应学习图像中不存在的未知模式的能力。
7.结论
在本文中,我们提出了一种预训练类型的缺陷检测算法,该算法可以处理各种对象和缺陷类型。通过提出的方法,我们验证了该算法还可以处理未知模式的对象和缺陷。
对于未来的前景,我们正在研究将其与更复杂的技术结合使用,以进行输入(照明,成像),机器人的驱动技术以及在线和其他学习,以处理具有更复杂设计的对象。





